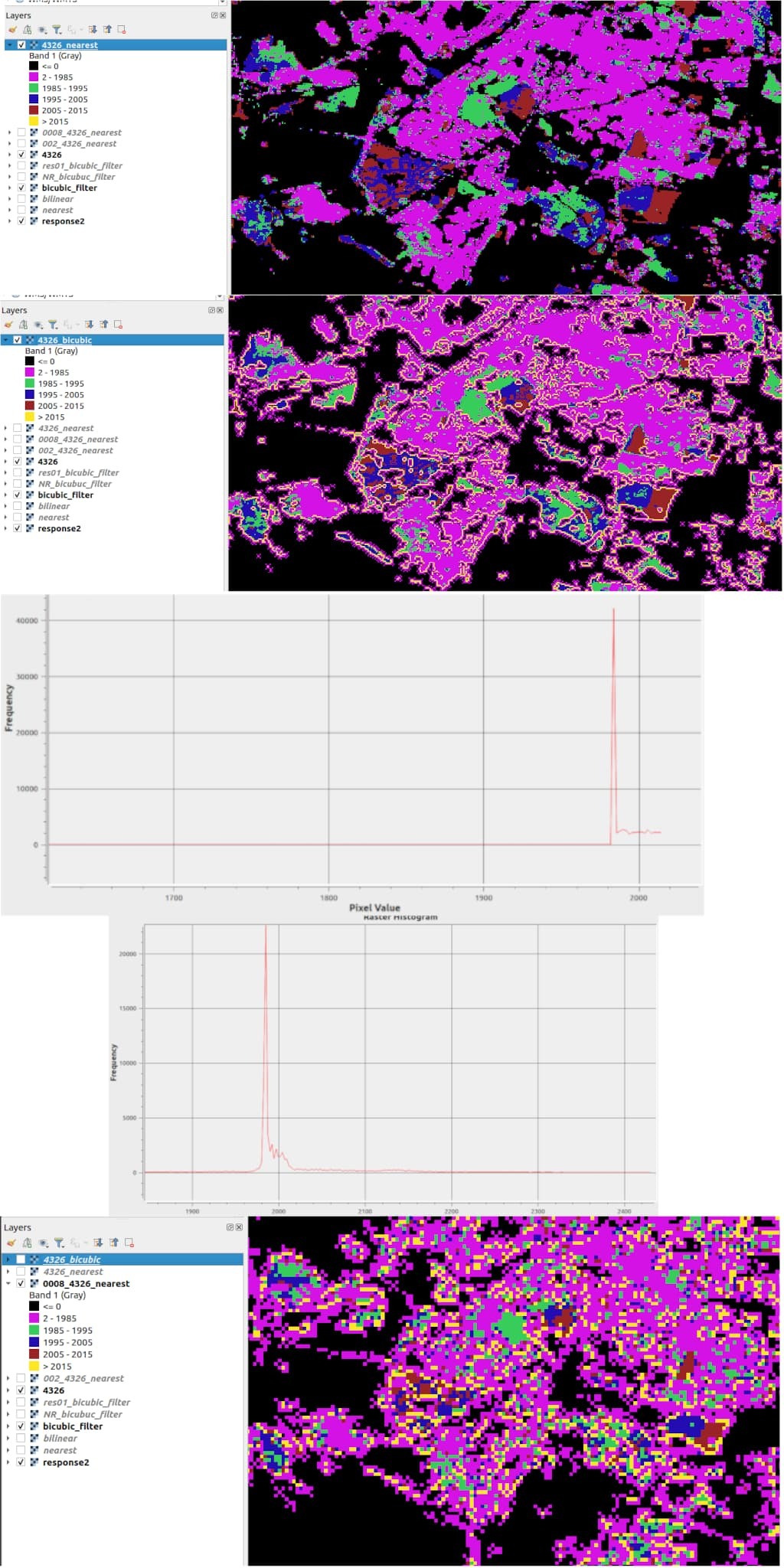
I am experimenting with the histogram calculations for a dataset that has year information per pixel.
The binning conceptually works nicely in order to evaluate how many pixels are available for each year.
The problem is using either width and height, or resx and resy i can’t manage to hit exactly the native resolution for a arbitrary bounds selection.
I am not sure what kind of resampling is done, but the year values are “corrupted” through the resampling, no longer showing expected range, but actually showing maxima of easily 100 years in the future.
Is there a way to set the resampling approach to at least nearest neighbor to make sure the values stay within the original range?
Or as maybe better alternative is there a way to make sure the exact native resolution is used for the statistical evaluation so that no resampling is needed at all?

Is there a way of specifying the resampling approach in the statistical api?
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
© 2026 Planet Labs PBC. All rights reserved.
| Privacy Policy | California Privacy Notice |California Do Not Sell
Your Privacy Choices | Cookie Notice | Terms of Use | Sitemap
