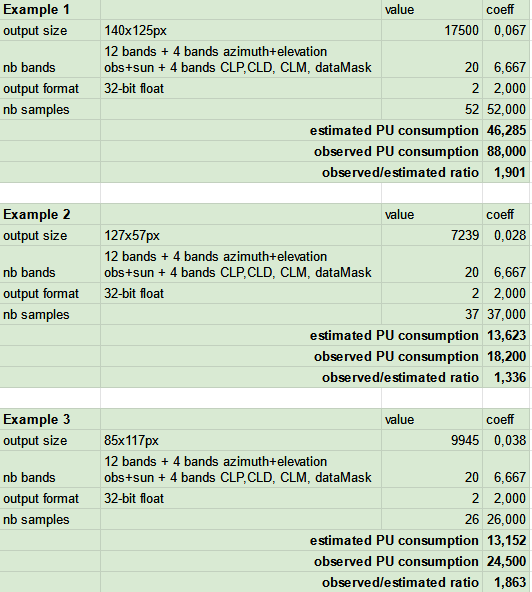
Hello. We are trying to calculate the Processing unit per hectare. Here is the example which we use for our calculations. Please, can you give me some feedback if we calculate it correctly for NDVI?
Your example on website:
Output size: 0,01 (20x20 px)
Input bands : 2/3
Output format: 1
Number of data sample : 1
Orthorecification : 1
PU = 0,01 x 2/3 x 1 x 1 x 1 = 0,0067 PU
The example on your website is designed for 20x20 px = 4h a = that is why Output size / multiplication factor : 0,01.
Also you define that the minimum value of multiplication factor is 0,01 which corresponds to an are of 0,25km2 = 25 ha.
Does it mean that the processing unit for 25ha in same example is the same ? 0,0067 PU ?
If I am correct, then processing unit for 250 ha would be : 0,0067 x 10 = 0,067 PU. Is that correct ?
Thank you for answering