Hello
Is it possible to specify the “Request id” to facilitate experiment tracking?
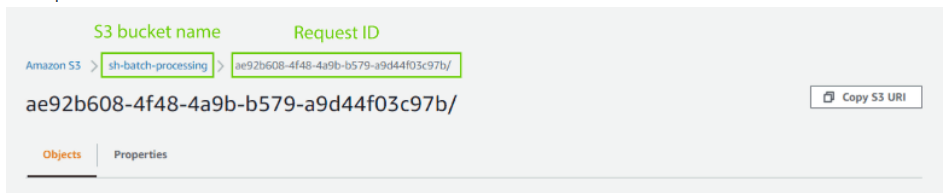
Thanks

Hello
Is it possible to specify the “Request id” to facilitate experiment tracking?
Thanks
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
©
Planet Labs PBC. All rights reserved.
|
Privacy Policy
|
California Privacy Notice
|
California Do Not Sell
Your Privacy Choices
|
Cookie Notice
|
Terms of Use
